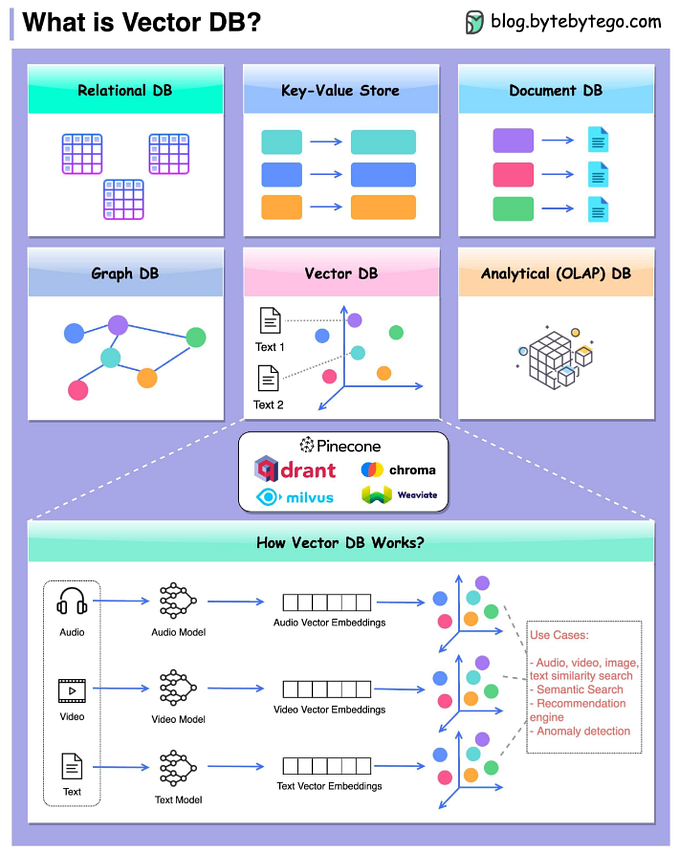
Handling schema drift for tables in Azure Synapse dedicated pool
Maintaining Azure Data Factory (ADF) pipelines for data sources having frequent schema drift is always challenging and cumbersome most of the times.
We have multiple ADF pipelines pulling data from various data sources. And, metadata changes happen frequently for the tables (like new columns added or changed) in the data sources.
- If you are using Data Flow in ADF, an option is provided to handle schema drift. When schema drift is enabled, all incoming fields are read from your source during execution and passed through the entire flow to the Sink. By default, all newly detected columns, known as drifted columns, arrive as a string data type.
- If you are using Serverless pool in Azure Synapse, spark code can be written to handle the schema drift. This is sample code.
%%pyspark
df = spark.read.load(‘abfss://<container name>@<ADLS storage account>.dfs.core.windows.net/file.csv’, format=’csv’
## If header exists uncomment line below
, header=True)
df.write.mode(“overwrite”).saveAsTable(“default.<table name>”)
None of the above options are suitable to us because we use “copy data” pipeline (not Data Flow) and we use “Dedicated pool” in Azure Synapse (not Serverless pool).
I developed a customized process for handling schema drift in our ADF pipelines. This process handles the schema drift problem by pulling the data only for the tables and the columns (in those tables) needed by end-users. So, any new column added to the data source will be added to Azure Synapse only if its needed by end-user. Any column deleted from the data source will be marked as inactive in Azure Synapse column tracking table.
For this process, I created two custom tables.
Table 1: This is used for holding columns’ details of all tables we pull data for. This table is used for tracking the column changes (via is_col_active). ADF pipeline pulls the data for the columns marked as active in this table.

Table 2: This is used for holding watermark values for all the tables we pull data for. Watermark values are used to perform delta data pulls from data sources on daily basis. This table is also used for tracking the active tables (via IsTableActive) needed by end-users. ADF pipeline pulls the data for the tables marked as active in this table.

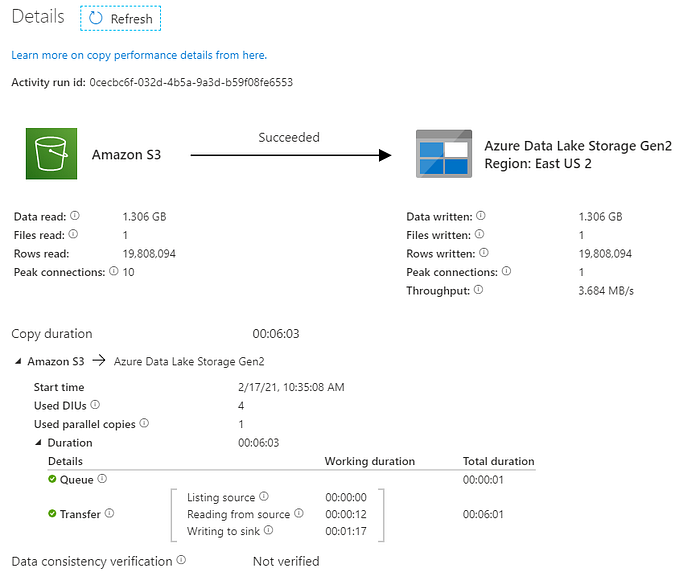
This is my pipeline design.


- LookupOldWatermark: This activity gets the previous day’s watermark values for all the active tables we need to pull data for. This SQL statement is executed in this activity.
SELECT [TableName], [WatermarkValue] FROM [dbo].[watermarktable] where [DataSource]=<data source name> AND [IsTableActive]=’Y’;
2. All these activities are executed for each table found in the output of above step, using ForEach loop.
→ LookupTabCols: This activity gets all columns that are marked as active for each table passed to ForEach loop. This SQL statement is executed in this activity.
DECLARE @col VARCHAR(8000)
SELECT @col = string_agg(cols.col_name,’,’) from dbo.all_tabs_cols cols
INNER JOIN dbo.watermarktable wm on cols.tab_name=wm.TableName
where cols.DB_NAME=<data source> and cols.tab_name=’@{item().tablename}’ and cols.is_col_active=’Y’
select @col as col_list;
→ CopyToParquet: This activity copies the data (for each table passed to ForEach loop) from data source to ADLS storage container in parquet format. This SQL statement is executed in this activity to get only the active columns from data source.
select @{activity(‘LookupTabCols’).output.value[0].col_list} from @{item().tablename} where <watermark column> > ‘@{formatDateTime(item().watermarkvalue, ‘yyyy-MM-dd hh:mm:ss’)}’
→ RemoveDupesFromParquet: This activity executes a Notebook to remove duplicates from parquet file. This PySpark code is executed to remove the duplicates.
%%pyspark
srcloc = ‘abfss://%s@abcdefgh.dfs.core.windows.net/%s/%s’ % (srccont,srcdir,srcfile)
destloc = ‘abfss://%s@abcdefgh.dfs.core.windows.net/%s/%s’ % (destcont,destdir,destfile)
df = spark.read.format(“parquet”).load(srcloc)
df = df.drop_duplicates()
df.write.format(“parquet”).mode(“overwrite”).save(destloc)
→ UpdateDedPoolTable: This activity executes a stored procedure that runs a “Merge” statement to update the data in “Dedicated pool” table. I created “External table” that points to the parquet files having duplicates removed. “Merge” statement uses the “External table” as source and “Dedicated pool” table as target for doing the data upsert.
→ LookupNewWatermarkValue: This activity gets the updated watermark value from the “Dedicated pool” table after the upsert is complete. This SQL statement is executed in this activity.
select max(<watermark column>) as NewWatermarkvalue from @{item().tablename}
→ UpdateWatermarkValue: This activity executes a stored procedure that updates watermark value for the table in [dbo].[watermarktable].
→ MoveFilesToDatedDirectory: This activity moves the parquet files (having no duplicates) to a different directory in ADLS storage. This is for ADLS storage container life-cycle management. This PySpark code is executed to move the parquet files.
%%pyspark
srcloc = ‘abfss://%s@abcdefgh.dfs.core.windows.net/%s/%s’ % (srccont,srcdir,srcfile)
destloc = ‘abfss://%s@abcdefgh.dfs.core.windows.net/%s/%s/’ % (destcont,destdir1,destdir2)
mssparkutils.fs.mv(srcloc,destloc,create_path=True,overwrite=False)
Disclaimer: The posts here represent my personal views and not those of my employer or any specific vendor. Any technical advice or instructions are based on my own personal knowledge and experience.