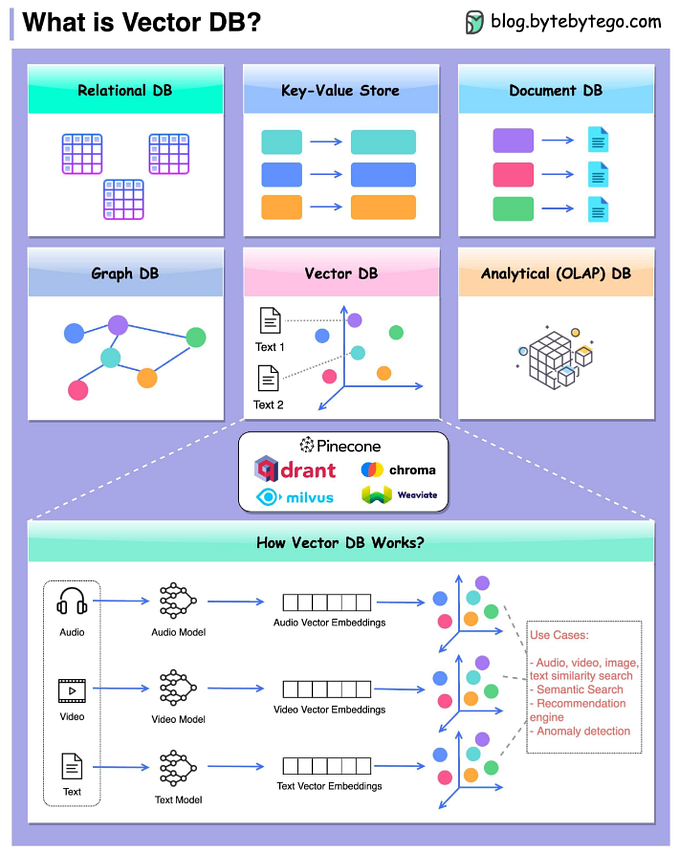
Confluent Cloud Kafka Metrics API and BigQuery to track cluster usage
Monitoring the usage of clusters on the Confluent Cloud Kafka platform is crucial from a FinOps perspective. It’s not just about tracking utilization, but also about providing accurate showbacks to internal customers for their consumption. This practice helps in optimizing resource allocation and ensuring cost efficiency within the organization. Additionally, having detailed insights into cluster utilization enables proactive capacity planning and better decision-making regarding resource scaling and allocation.
Confluent provides a way for the team to track the usage of dedicated clusters in the Confluent Cloud. This link describes a model for monitoring usage and implementing showbacks of Confluent Cloud Dedicated Cluster costs.
I took this model and added some additions to it to get the comprehensive details we need to track the cluster’s usage at the user level.
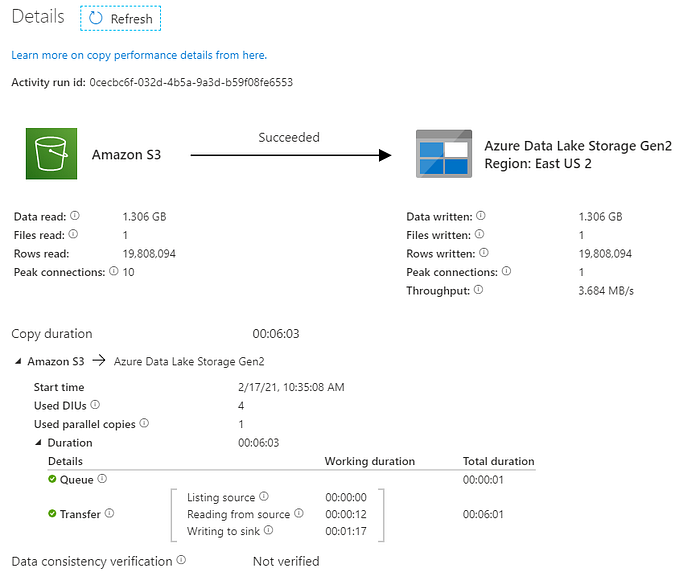
I’m getting the “request bytes” and “response bytes” metrics by calling the API provided by Confluent and loading that data into a BigQuery table. This approach allows visualization to be built on top of the BigQuery table.
The script that gets the metric details is executed daily through the GitHub Actions workflow.

Disclaimer: The posts here represent my personal views, not those of my employer or any specific vendor. Any technical advice or instructions are based on my knowledge and experience.