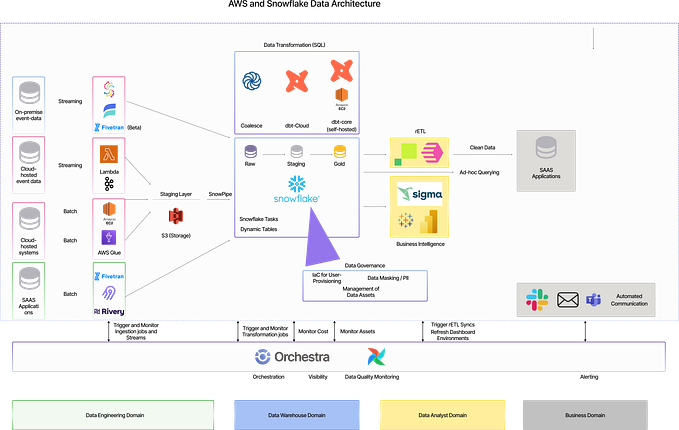
ADF pipeline to copy a file from AWS S3 to ADLS Gen2
The process to copy a file from AWS S3 bucket to Azure Data Lake Storage (ADLS) Gen2 storage account using Azure Data Factory (ADF) is easy to implement.
It involves these steps.
- Create AWS S3 bucket
- Get Access key ID and Secret access key to access AWS S3 bucket
- Create ADLS Gen2 storage account
- Create linked services for AWS S3 and ADLS Gen2 in ADF
- Create datasets for AWS S3 and ADLS Gen2 in ADF
- Create pipeline in ADF for copying the file from AWS S3 to ADLS Gen2
I used NYC taxi FHV public dataset file for the purpose of my testing.
Create AWS S3 bucket
For the purpose of my testing, I created AWS S3 bucket with public access unblocked. This is not at all recommended for regular storage accounts.
I uploaded a New York taxi trip data file to the S3 bucket.



Get Access key ID and Secret key to access AWS S3 bucket
We need access key and secret access key for the account having AWS S3 bucket, to be able to copy the file from AWS S3 bucket to ADLS Gen2 container through ADF.
We can get the keys from Security credentials in AWS Identity and Access Management (IAM). Its better to download the key file.

Create ADLS Gen2 storage account
For the purpose of my testing, I created the storage account with Public endpoint as the connectivity method. This is not at all recommended for regular storage accounts.




Create linked services for AWS S3 and ADLS Gen2 in ADF
Linked services are much like connection strings, which define the connection information needed for Data Factory to connect to external resources.
For AWS S3 linked service, you enter the access key ID and secret access key in the linked service setup window. Testing the connection helps to verify the linked service setup.

For ADLs Gen2 linked service, you can select the ADLS Gen2 storage account created in earlier step. Testing the connection helps to verify the linked service setup.

Create datasets for AWS S3 and ADLS Gen2 in ADF
Dataset represents the structure of the data within the linked data stores. ADF supports many different types of datasets, depending on the data stores you use.


Create pipeline in ADF for copying the file from AWS S3 to ADLS Gen2
A pipeline is a logical grouping of activities that together perform a task. The pipeline allows you to manage the activities as a set instead of each one individually. You deploy and schedule the pipeline instead of the activities independently.
For the purpose of my testing, I created “Copy Data” pipeline with AWS S3 bucket as my source and ADLS Gen2 storage account as my sink/target.


Once the pipeline is created, you just trigger the debug run to start the copy task.

Disclaimer: The posts here represent my personal views and not those of my employer or any specific vendor. Any technical advice or instructions are based on my own personal knowledge and experience.



![Azure End-to-End Data Engineering Project: Medallion Architecture with Databricks [Part 2]](https://miro.medium.com/v2/resize:fit:679/0*m8-NjvFFlKGa1tku.jpeg)